

Contents
hide
What is a Graph Database?
: For upon |Very simply, a graph database is a database designed to treat the relationships between data as equally important to the data itself. It is intended to hold data without constricting it to a pre-defined model. Instead, the data is stored like we first draw it out – showing how each individual entity connects with or is related to others.
Why Graph Databases?
We live in a connected world! There are no isolated pieces of information, but rich, connected domains all around us. Only a database that natively embraces relationships is able to store, process, and query connections efficiently. While other databases compute relationships at query time through expensive JOIN operations, a graph database stores connections alongside the data in the model.
Accessing nodes and relationships in a native graph database is an efficient, constant-time operation and allows you to quickly traverse millions of connections per second per core.
Independent of the total size of your dataset, graph databases excel at managing highly connected data and complex queries. With only a pattern and a set of starting points, graph databases explore the neighboring data around those initial starting points — collecting and aggregating information from millions of nodes and relationships — and leaving any data outside the search perimeter untouched.
The Property Graph Model
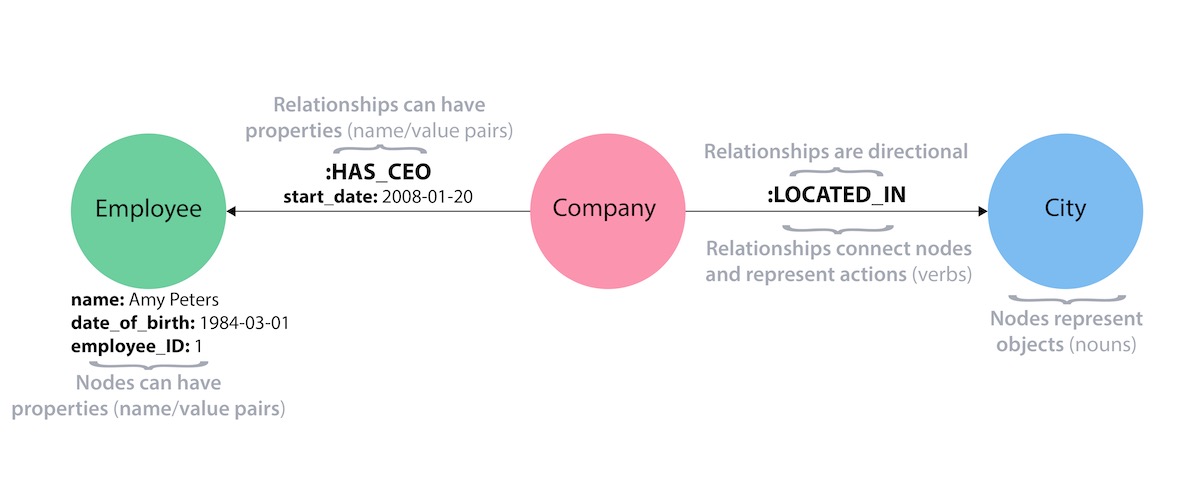
As with most technologies, there are a few different approaches to what makes up the key components of a graph database. One such approach is the property graph model, where data is organized as nodes, relationships, and properties (data stored on the nodes or relationships).
We will cover this model in more detail in the Data Modeling section of these guides, but for now, we will briefly define the components that make up the property graph model.
Nodes are the entities in the graph. They can hold any number of attributes (key-value pairs) called properties. Nodes can be tagged with labels, representing their different roles in your domain. Node labels may also serve to attach metadata (such as index or constraint information) to certain nodes.
Relationships provide directed, named, semantically relevant connections between two node entities (e.g. Employee WORKS_FOR Company). A relationship always has a direction, a type, a start node, and an end node. Like nodes, relationships can also have properties. In most cases, relationships have quantitative properties, such as weights, costs, distances, ratings, time intervals, or strengths. Due to the efficient way relationships are stored, two nodes can share any number or type of relationships without sacrificing performance. Although they are stored in a specific direction, relationships can always be navigated efficiently in either direction.
Building blocks of the property graph model (click to zoom)
What is Neo4j?
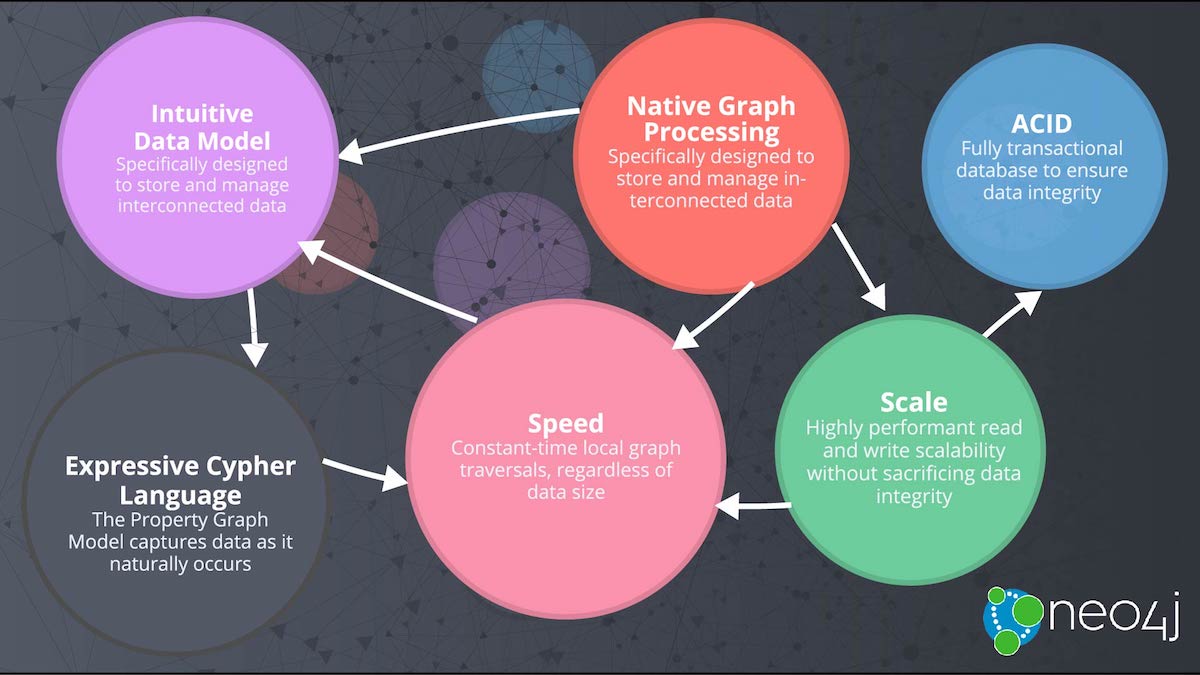
Neo4j is an open-source, NoSQL, native graph database that provides an ACID-compliant transactional backend for your applications. Initial development began in 2003, but it has been publicly available since 2007. The source code, written in Java and Scala, is available for free on GitHub or as a user-friendly desktop application download. Neo4j has both a Community Edition and an Enterprise Edition of the database. The Enterprise Edition includes all that Community Edition has to offer, plus extra enterprise requirements such as backups, clustering, and failover abilities.
Neo4j is referred to as a native graph database because it efficiently implements the property graph model down to the storage level. This means that the data is stored exactly as you whiteboard it, and the database uses pointers to navigate and traverse the graph. In contrast to graph processing or in-memory libraries, Neo4j also provides full database characteristics, including ACID transaction compliance, cluster support, and runtime failover – making it suitable to use graphs for data in production scenarios.
Some of the following particular features make Neo4j very popular among developers, architects, and DBAs:
- Cypher, is a declarative query language similar to SQL but optimized for graphs. Now used by other databases like SAP HANA Graph and Redis graph via the open cipher project.
- Constant time traversals in big graphs for both depth and breadth due to efficient representation of nodes and relationships. Enables scale-up to billions of nodes on moderate hardware.
- Flexible property graph schema that can adapt over time, making it possible to materialize and add new relationships later to shortcut and speed up the domain data when the business needs change.
- Drivers for popular programming languages, including Java, JavaScript, .NET, Python, and many more.
Related Posts
Neo4j Use Cases
Neo4j is used today by thousands of companies and organizations in almost all industries, including financial services, government, energy, technology, retail, and manufacturing. The thriving, active community surrounding the technology continues to help us improve our products and services for developers and businesses alike.
Learn more about different use cases and companies using them in the video below.
Resources
- Video Series: Intro to Graph Databases
- Free eBook: O’Reilly Graph Databases
- DZone: Graph Databases for Beginners
- Training: Online Intro Course
The article was originally published here.
Comments are closed.